
For some products, having your own language that your customers can use to be productive, or make your product that much more powerful, is a Domain Specific Language. Think Atlassian’s Jira Query Language, Github’s filter feature etc.
Why not hand-roll your own parser? – well, in 99% of cases, you wouldn’t really need the extra granular control to squeeze out every bit of performance out of a parser, or nor will you need extra features that Antlr would not be able to provide – these types of requirements are usually reserved for products that are sold as a language themselves i.e. real programming languages like C#, JavaScript etc.
A pre-requisite to this guid is having antlr4 tool itself installed. You should be able to run antlr4 and grun commands in your terminal after following the getting started guide.
Starting With Something Simple
So, let’s have some simple fictional requirements – let’s say we’re a job board that allows employers to search for potentially suitable candidates.
As a power user, I want to be able to write an expression for searching candidates that looks like:
(
@current_job_title contains "software developer"
or @current_job_title contains "software engineer"
)
and @experience_years > 5
and @salary < 90000
To put this as language syntax requirements and what we need to support, we need to be able to:
- support types of
numberandstring - supports operators
contains,=,>,<,>=,<=and!= - be able to support boolean operators
andandor - be able to find if a substring exists in a string
- support properties using
@variable_name - group sub expressions with parenthesis
( expr )
Lexer Rules
Simply put, a lexer turns a stream of text into a stream of tokens for the parser to consume, it is the first part of the parsing process.
Our lexer should be fairly small and look like this:
/*
LEXER RULES
*/
// boolean operators
And: 'and';
Or: 'or';
// operators
GreaterThan: '>';
GreaterThanEqual: '>=';
LessThan: '<';
LessThanEqual: '<=';
Equal: '=';
NotEqual: '!=';
Contains: 'contains';
OpenParen: '(';
CloseParen: ')';
// operands
Number: [0-9]+;
String: '"' ( '\\"' | ~["\r\n] )*? '"';
Property: AT PROPERTY_NAME;
WhiteSpace: [ \t\f\r\n]+ -> channel(HIDDEN); // skip whitespaces
Discardable: . -> channel(HIDDEN); // keeping whitespace tokenised makes it easier for syntax highlighting
fragment PROPERTY_NAME: [a-z_]+;
fragment AT: '@';
We’ve defined all the possible tokens that can exist in the language that we’re implementing.
Parser Rules
Now, this is the more interesting part – the parser rules. The parser rules define what a valid state for a given grammar is.
Our parser rules looks like this:
/*
PARSER RULES
*/
expr: predicate EOF;
predicate
: predicate booleanOperator predicate
| OpenParen predicate CloseParen
| operand operator operand
;
booleanOperator
: And
| Or
;
operator
: GreaterThan
| LessThan
| GreaterThanEqual
| LessThanEqual
| Equal
| NotEqual
| Contains
;
operand
: Property
| String
| Number
;
You should now have a grammar file predicate.g4 that has content shown below:
grammar Predicate;
/*
PARSER RULES
*/
expr: predicate EOF;
predicate
: predicate booleanOperator predicate
| OpenParen predicate CloseParen
| operand operator operand
;
booleanOperator
: And
| Or
;
operator
: GreaterThan
| LessThan
| GreaterThanEqual
| LessThanEqual
| Equal
| NotEqual
| Contains
;
operand
: Property
| String
| Number
;
/*
LEXER RULES
*/
// boolean operators
And: 'and';
Or: 'or';
// operators
GreaterThan: '>';
GreaterThanEqual: '>=';
LessThan: '<';
LessThanEqual: '<=';
Equal: '=';
NotEqual: '!=';
Contains: 'contains';
OpenParen: '(';
CloseParen: ')';
// operands
Number: [0-9]+;
String: '"' ( '\\"' | ~["\r\n] )*? '"';
Property: AT PROPERTY_NAME;
WhiteSpace: [ \t\f\r\n]+ -> channel(HIDDEN); // skip whitespaces
Discardable: . -> channel(HIDDEN); // keeping whitespace tokenised makes it easier for syntax highlighting
fragment PROPERTY_NAME: [a-z_]+;
fragment AT: '@';
Run a few tests
Now, with predicate.g4 defining our grammar, we can test our grammar by running following commands:
for cmd:
antlr4 -Dlanguage=Java -o .java Predicate.g4 -no-listener -visitor ^
& javac .java/*.java ^
& pushd .java ^
& grun Predicate expr -gui
or bash:
antlr4 -Dlanguage=Java -o .java Predicate.g4 -no-listener -visitor \
& javac .java/*.java \
& pushd .java \
& grun Predicate expr -gui
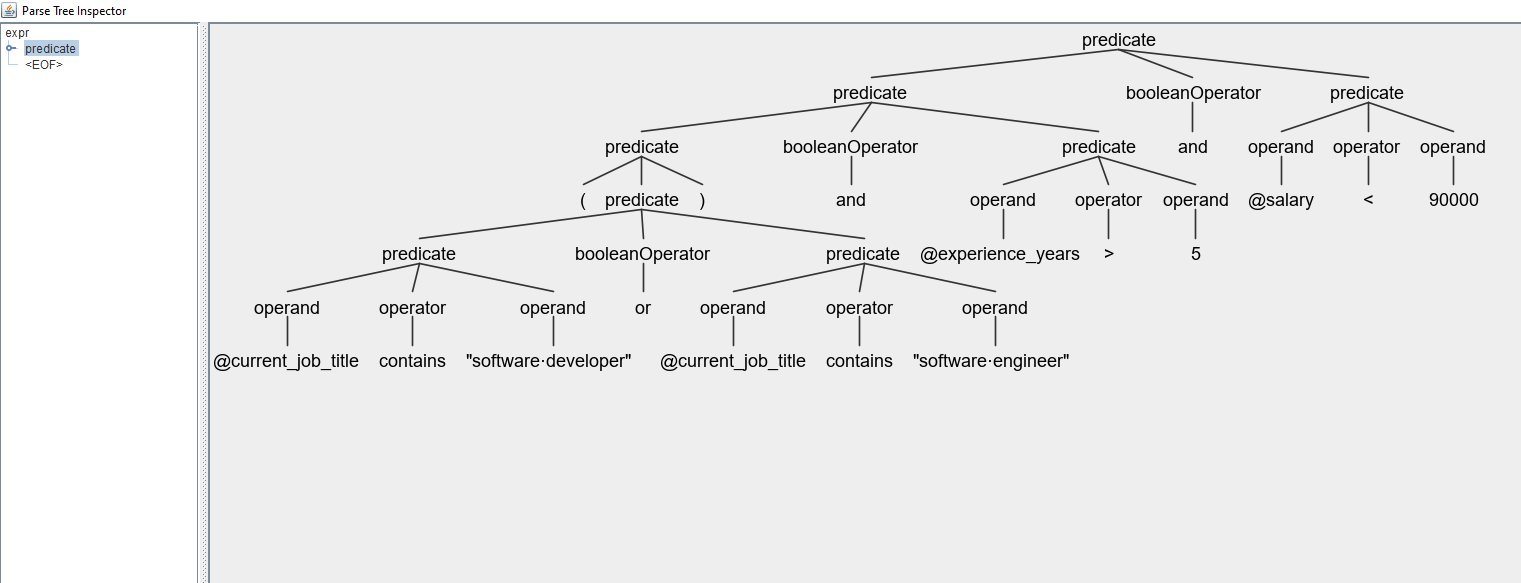
Now, you will be able to type in some text to try your grammar out, for example:
(@current_job_title contains "software developer"
or @current_job_title_contains "software enginner")
and @experience_in_years > 5
and @salary > 90000
Once, then for windows, you enter your input by adding EOF, this is CTRL+Zin windows, and CTRL+D on unix.
You should now see your text parsed as a tree.
Next Up
Next part of this post, will include:
– building the actual parser
– adding extra abstraction over antlr to simplify the parse-tree and a few other benefits
– build an evaluator that evaluates a search string going through a parser and finally, searching and returning response from elastic search
